

OpenAI ha lanzado GPT-5.3 Codex Spark, una versión optimizada de su modelo de lenguaje para desarrollo de software que promete eliminar las esperas al escribir código. Este nuevo modelo es capaz de generar código hasta 15 veces más rápido que la versión estándar de GPT-5.3 Codex, ofreciendo una experiencia que la compañía describe como «casi instantánea».
Diseñado para el «Bucle Interactivo»
A diferencia de los modelos tradicionales que se toman su tiempo para razonar, Spark está pensado para integrarse en el flujo de trabajo del desarrollador en tiempo real:
- Ventana de contexto: Posee una capacidad de 128k tokens, optimizada para una inferencia ultra veloz.
- Control total: Los usuarios pueden interrumpir o redirigir a la IA mientras escribe, facilitando la edición de interfaces o el refinamiento de lógica sobre la marcha.
- Hardware de vanguardia: Es el primer fruto de la colaboración con Cerebras, funcionando sobre el Wafer Scale Engine 3 (WSE-3), un chip del tamaño de una oblea con 127 petaFLOPS de potencia.
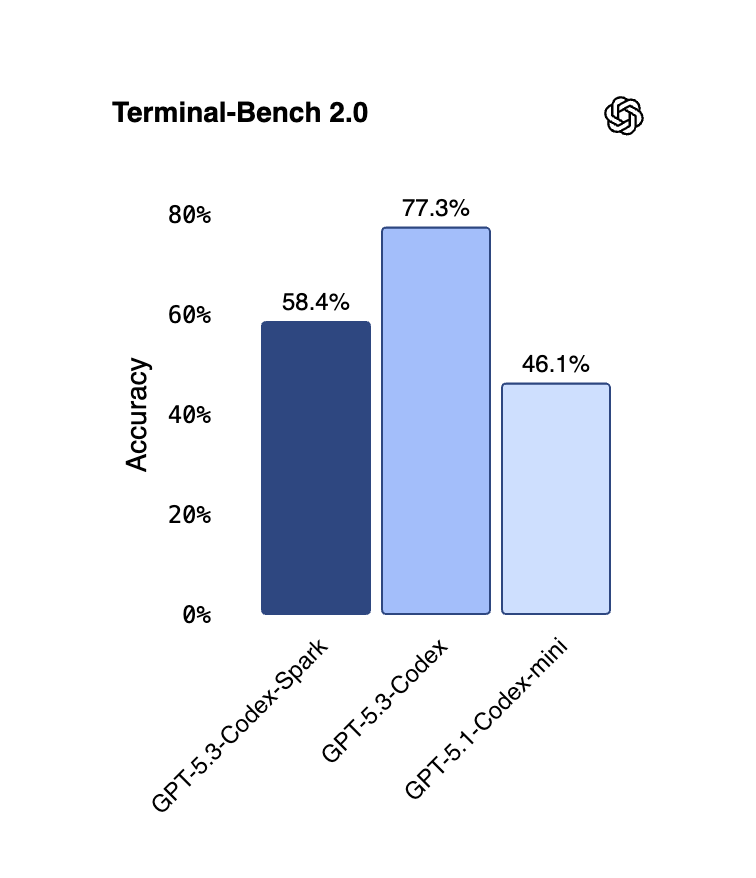
La velocidad tiene un precio: El riesgo de errores
No todo es perfecto. La baja latencia de Spark es un «arma de doble filo»:
- Sin validación automática: Para ganar velocidad, el modelo no realiza pruebas de validación por defecto a menos que se le indique.
- Correcciones manuales: Al no razonar profundamente cada línea, el tiempo que ahorras en la generación podrías perderlo corrigiendo errores de lógica que un modelo más lento habría detectado.
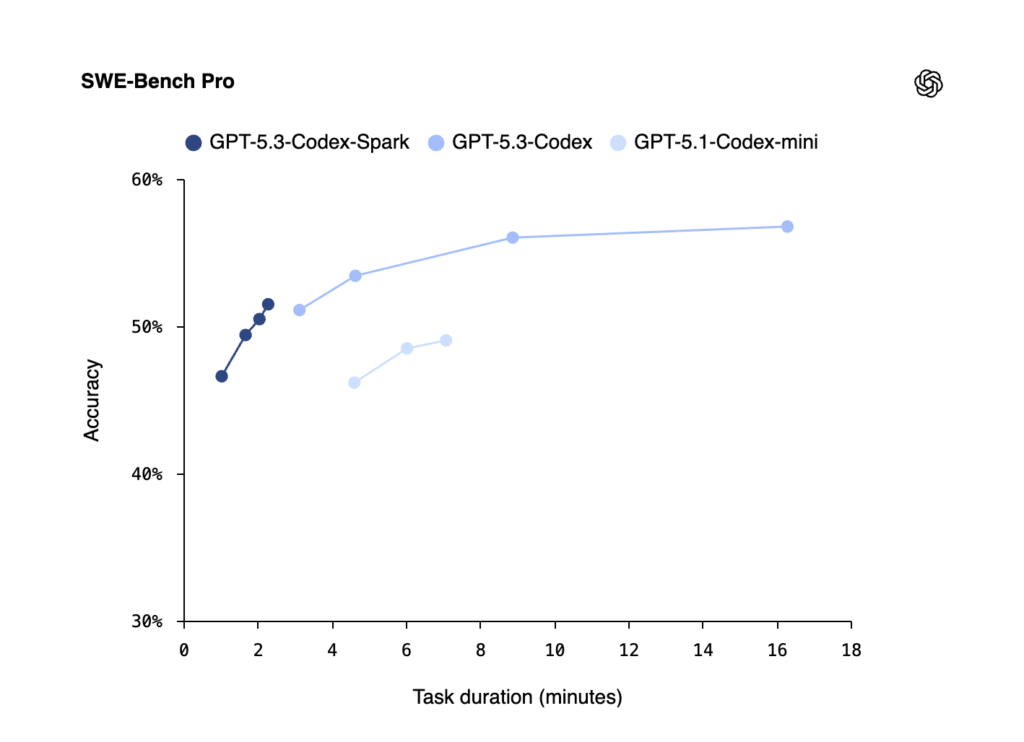
Spark no viene a sustituir a Codex, viene a ayudar
OpenAI ha dejado claro que Spark es un complemento, no un reemplazo. Mientras Spark se encarga de las tareas rápidas e interactivas, el modelo Codex estándar sigue siendo el «rey» de la precisión para tareas largas y complejas.
El veredicto técnico del Gurú
Lo que hace realmente especial a Spark no es solo el software, sino su arquitectura de servidores. OpenAI ha reescrito la pila de inferencias y optimizado la comunicación cliente-servidor para reducir la latencia al mínimo absoluto. El uso del chip Cerebras WSE-3 con su ancho de banda de 21 petabytes por segundo es la clave para que la IA responda en una fracción de segundo.
Es la herramienta ideal para prototipado rápido, pero ¡ojo!, revisa siempre el código antes de darle a «ejecutar». ¡Te leemos en los comentarios! Y no te olvides de seguir a Gurú Tecno en YouTube, Instagram y Facebook.